
RXBio Translates Sequence to Science and Industry

RuiXing Biotech, relying on over ten years of experience in omics research and bioinformatics analysis, has launched a full-process scientific research solution for “Single-Cell Big Data”. Based on the public databases of single-cell spatial multi-omics or your own data, we conduct multi-dimensional in-depth analysis to dig for innovative findings and organize them into a complete story line with clear logic, achieving efficient transformation from data to papers or grant proposals.
It is especially suitable for:
▷ Beginners who have access to public data but don’t know where to start.
▷ Busy research groups with mountains of data piled up.
▷ Research groups whose research has been criticized for lacking innovation.
▷ Principal Investigators (PIs) who want to publish articles but are short of technical backbones.
1. SCI-level charts: Central graphics, English legends for grouped figures, etc.
2. Article framework: Innovation findings in the writing framework of SCI papers.
3. Experimental design: Verification of experimental design to match different SCI levels.
4. Submission guidance: Free guidance on manuscript modification suggestions for 2 times, and recommendation of 2 – 3 target journals for submission.
5. Efficient delivery: The project plan will be provided within 5 working days, and the fastest delivery time will be within 30 working days.
Data will never go out of date. Instead, it will be reborn with new perspectives.
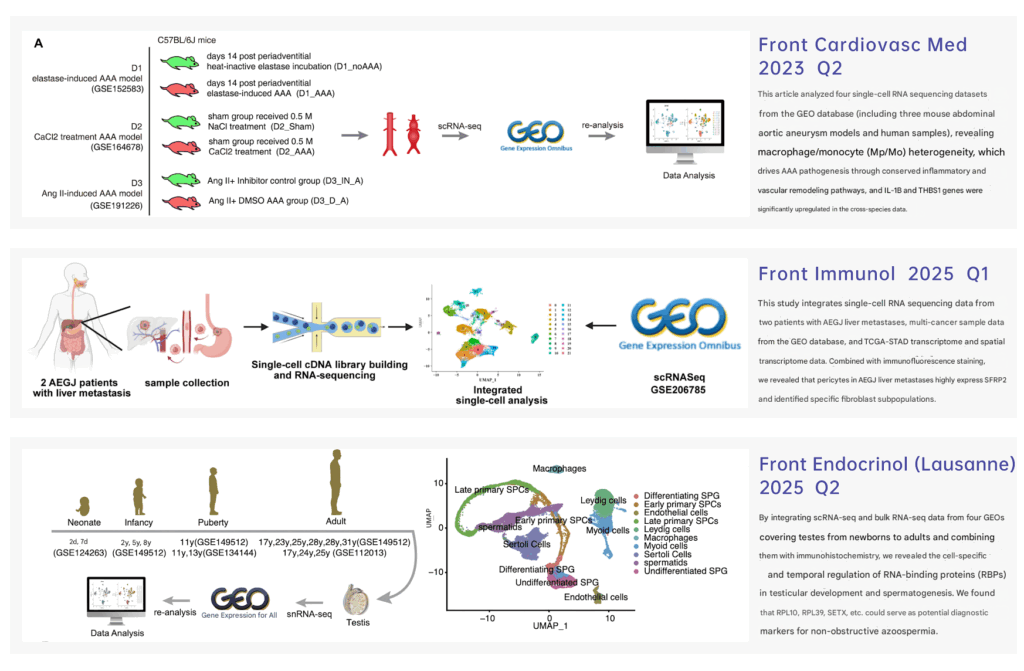
Globally, single-cell sequencing has accumulated several petabytes of data, covering more than 300 disease types such as cancer and neurological disorders, and has constructed the most elaborate “cellular map” of life to date. These vast amounts of data are not only the achievements of the past but also the fuel for future innovation. By combining multi-omics and conducting cross-disease correlation analyses on the existing data, new problems can be solved, such as unlocking new biomarkers, drug targets and treatment mechanisms.
✔ Cost savings for experiments
▪ Zero sequencing cost: There is no need for sample collection, thus saving funds.
▪ Risk control: Avoid experimental risks, directly obtain mature data, and quickly promote scientific research.
✔ Driven by massive data
▪ Massive data support: Integrate multiple public data sets of single-cell and spatial omics.
▪ Explore new directions: Through data mining, focus on cell subsets, gene interactions or regulatory networks that were previously overlooked, and use existing data to analyze new problems.
✔ Efficient transformation of achievements
▪ Complete story line: Transform bioinformatics data into the story line for papers and support the design of wet experiments.
▪ High-level scientific research achievements: Dig out innovative highlights to assist in grant proposal applications and paper publications.